Next-Gen Data Access: dbVisitor

This article is generated by AI translation.
Classic frameworks like Hibernate and MyBatis were built for an RDBMS-only world. As data diversifies into NoSQL, NewSQL, and vector stores, the real challenge shifts to unified access across all of them.
I. The Old Generation
Talking about "old generation" data access libraries is not derogatory, but refers to the era background and core mission of their birth.
In the past and present, MyBatis, Hibernate, JPA (Hibernate), Spring JDBC Template, and Apache Commons DbUtils ruled the Java developers' toolbox. Their common characteristics are very obvious:
- Relational Databases: Their original design intention was to better operate databases like Oracle, MySQL, PostgreSQL, etc. The core logic, whether it is ORM mapping or SQL templates, closely revolves around the SQL standard.
- Exclusivity: When NoSQL rose, these frameworks seemed powerless. So we saw proprietary SDKs like MongoDB Java Driver, Elasticsearch RestHighLevelClient, etc.
This situation led to a phenomenon: either exclusive or leaning towards pure relational databases. If your application needs to query both MySQL and Elasticsearch, you usually need to introduce two completely different technology stacks and write two sets of code with widely different styles.
II. Attempts to Bridge the Gap
Database technology has been constantly iterating. Document databases (MongoDB), search engines (Elasticsearch/OpenSearch), key-value stores (Redis), time-series databases, and even current vector databases are swarming in.
Facing these "new things", our familiar "old recipes" are also trying to solve new problems. So we saw a series of actions trying to bridge the gap:
- Easy-ES: Attempts to use MyBatis-Plus habits to operate Elasticsearch, letting developers operate indexes like operating database tables.
- Hibernate OGM: Attempts to extend the JPA standard to the NoSQL field, mapping non-relational data with annotations.
- Spring Data: Attempts to cover underlying implementation differences through unified Repository interface abstractions (such as
JpaRepositoryvsMongoRepository).
However, although these efforts have alleviated the problem to some extent, it is still difficult to cover the core dilemma:
-
Applying SQL Thinking: SQL is the lingua franca of relational databases, but forcing SQL or tabular thinking onto data with nested structures, inverted indexes, or graph relationships. Tools like Easy-Es are convenient, but when dealing with ES specific aggregations or complex DSLs, one often needs to fall back to native QueryDSL.
-
Middleware's Attitude towards JDBC: JDBC is one of the most successful abstractions in the Java world, but it has been deeply branded with relational databases.
- Elasticsearch: Once tried to provide JDBC support, but with many limitations (does not support nested object complex queries), and even planned to deprecate the SQL plugin at one point.
- MongoDB: Although there is a commercial version of the JDBC driver, the community ecosystem generally prefers using MongoTemplate or raw BSON API.
-
Continuous Fragmentation at the API Interface Level: Despite encapsulations like Spring Data, the underlying fragmentation still persists.
- Relational Database:
mapper.selectById(id) - MongoDB:
mongoTemplate.findById(id, class) - Elasticsearch:
client.get(new GetRequest(index, id))
This fragmentation not only increases learning costs but also complicates architectural design. We seem to have a pile of tools, but still lack a true "One API" to unify all data access.
- Relational Database:
III. One APIs Access Any DataBase
Since we have moved towards diversification, the Data Access Layer (DAL) must also evolve. The mission of the new generation data access library should be to re-standardize and unify data access.
We should no longer ask "What database is this?", but "What operation do I want to perform on this data source?".
Inheriting the universal spirit of JDBC and SQL, but breaking its shackles on relational databases, this is the goal of the new generation data access library. Summarized in one sentence: "One APIs Access Any DataBase".
IV. Technical Choices and Feasible Paths
To realize this grand vision, there are two main technical paths to choose from:
Path 1: Unified DSL
This path attempts to define a "universal language" that can express relational queries, document retrieval, graph traversal, and other logic simultaneously.
-
SQL-like Unified DSL: The essential difficulty lies in the difference in application scenarios, making it difficult to have a unified DSL applicable in all scenarios. For example, Oracle, MongoDB, Elasticsearch, and even Redis reaching a consensus at the syntax level.
-
Natural Language: A bolder hypothesis is to directly interpret natural language into a physical execution plan executable by the database engine based on LLM Large Language Models, that is:
Natural Language -> AI -> Operator Tree -> Storage Engine. AI acts as a Parser and Optimizer in this process, directly driving the database kernel to run specific physical tasks. But at present, AI still has "hallucination" risks when dealing with semantic precision, data access security, and complex logical reasoning. Applying uncertain AI reasoning directly to the deterministic data storage kernel will be a highly adventurous act. Therefore, it is more seen as an auxiliary tool (Copilot), rather than a low-level, deterministic data access standard.
Path 2: Abstraction of Basic Paradigms
Operation is the essence of data access. Compared to inventing a new language or relying on AI, it appears more pragmatic and controllable. Whether data exists in MySQL rows, Redis Keys, Elasticsearch Documents, or Neo4j nodes.
Applications' usage scenarios for data almost always fall into the four basic paradigms of Create, Delete, Update, and Read (CRUD).
-
Behavior-Centric: Unlike SQL which focuses on "how to describe data", the unified API focuses on "what the application wants to do with data". "Get object by ID" is a generic intent, whether the underlying is
SELECT * FROM table WHERE id=?orGET /index/_doc/id, its business semantics are completely consistent. -
Escape Hatch: Of course, simple CRUD cannot cover 20% of complex scenarios in real business (such as deep aggregation, graph algorithm analysis). Therefore, the unified API scheme must include an escape hatch mechanism. When standard CRUD cannot meet the demand, developers can use JDBC's
Statementinterface to directly issue proprietary DSLs (such as Elasticsearch JSON Query) or standardized SQL. The underlying adapter is not only responsible for translating standard CRUD, but also allows passing through native APIs or SDK calls, ensuring simplicity for simple scenarios and power for complex scenarios. -
Adapter Pattern: By defining a set of standard APIs (such as
insert,update,query), we can dynamically "translate" these standard requests into dialects (Dialect) of different data sources on the bottom layer through the Adapter Pattern.
V. New Generation Data Access Library
I believe that the "New Generation Java Data Access Library" should take One APIs Access Any DataBase as its core vision, targeting to provide developers with a unified, simple, and efficient data operation experience by shielding underlying data source differences through standardized APIs.
It should no longer distinguish "Is this an ORM" or "Is this a Client", it is the unified gateway for applications to access data.
VI. dbVisitor's Technical Attempt
dbVisitor is a technical attempt born based on this concept. Its architectural design is very unique and can be summarized as: API Access Library + JDBC Driver double-layer adapter architecture.
1. API Access Library: Providing Unified API
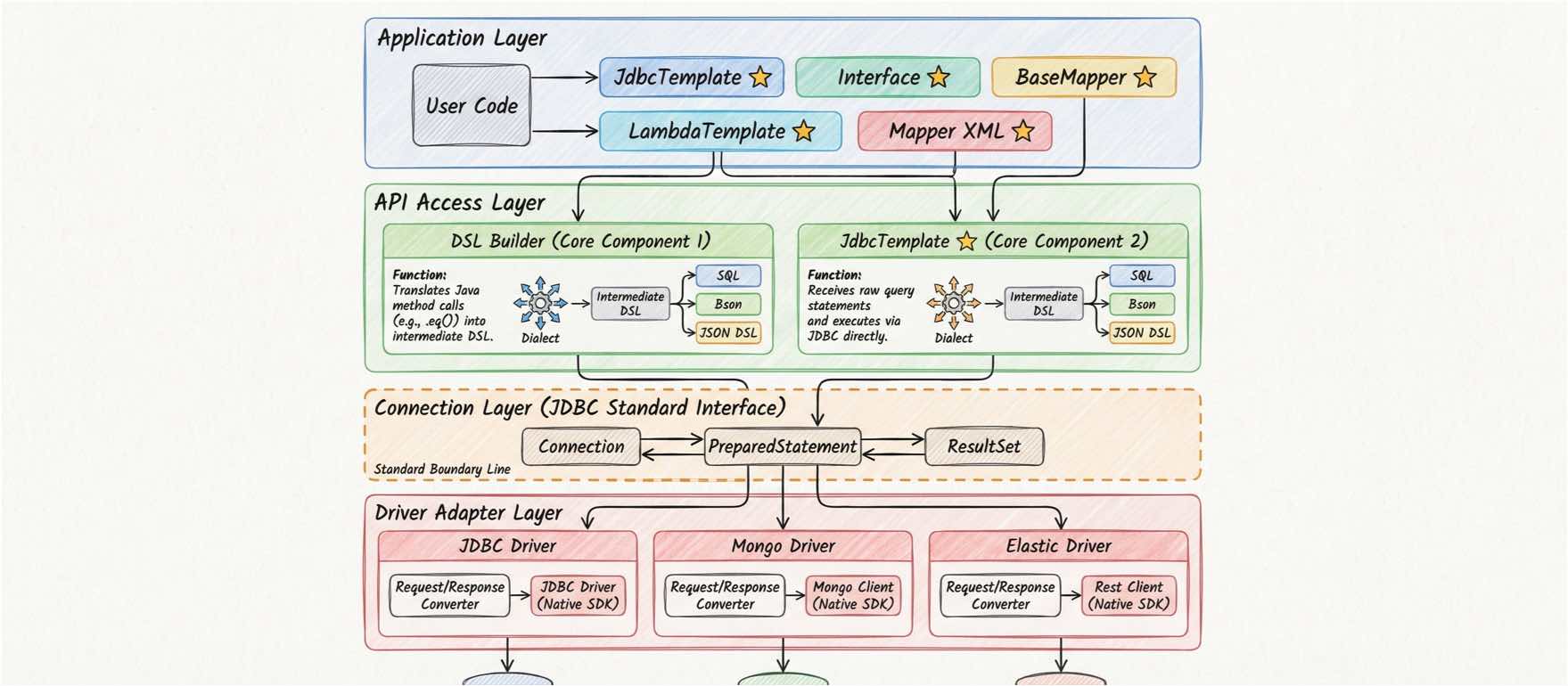
dbVisitor's data access layer does not rely on specific SQL syntax, but provides highly abstract APIs. For example: Query Builder
// Whether MySQL or MongoDB, the code looks the same
lambdaTemplate.lambdaQuery(User.class)
.eq(User::getAge, 18)
.list();
This layer is responsible for shielding the mapping differences between Java objects and data models.
In this process, Dialect plays a key translator role. It is responsible for generating proprietary DSLs (such as MySQL's SQL, MongoDB's BSON Command, Elasticsearch's JSON DSL) that the target data source can understand based on the calling behavior of the upper-layer unified API (such as .list(), .eq()).
These generated DSLs will then be issued to the JDBC Driver Adapter Layer, executed by the corresponding driver executor for final data interaction. This mechanism ensures the purity of business code while retaining precise control over underlying features.
2. JDBC Driver Adapter
Selective implementation under standards, this is the most innovative place of dbVisitor. It did not reinvent the wheel to write a set of private protocol Drivers, but chose to reuse JDBC standard interfaces, but extended and adapted its connotation.
dbVisitor's solution is to introduce a lightweight driver adapter framework. It encapsulates JDBC's cumbersome state management and complex interface specifications into a simple Request/Response Model.
Developers do not need to implement a complete JDBC specification, but only need to focus on core data interaction logic and implement the Request/Response Model.
This simplification greatly reduces the cost of adapting new data sources, thereby enabling quick adaptation to most data access needs.
Through this "old wine in a new bottle" approach, dbVisitor preserves JDBC ecosystem compatibility (you can manage ES connections directly with Druid connection pool) and achieves native-level support for NoSQL.
VII. Current Challenges
Although dbVisitor's double-layer adapter architecture solves most general problems, we still face some objective challenges on the journey to realize "One API":
-
Encapsulation and Penetration: The Request/Response model greatly simplifies adapter development, but no abstraction can perfectly cover all underlying features. When developers need to use an extremely special feature of a certain data source, the current solution is to allow using JDBC's
unwrapmethod to reach the underlying SDK directly. Although this breaks encapsulation to some extent and is not a recommended usage, providing this "backdoor" ensures that problems can still be solved in extreme scenarios. -
DSL Dilemma: Not all NoSQLs have a perfect query language. For those databases without DSLs, dbVisitor has to adopt a compromise solution: use DSL syntax to imitate SDK's API call structure. The benefit of this is retaining usage habits close to the official ones, lowering the cognitive threshold. But the downside is also obvious: SDK API differences between different versions or even incompatible API structures. This weakens the standardization degree and stability of DSL itself and increases cognitive burden. This problem can only hope that database vendors can have a standard query syntax belonging to themselves, such as Elasticsearch's QueryDSL.
-
Sync vs Async Trade-off: The JDBC protocol is designed based on blocking I/O, which means dbVisitor currently mainly serves classic synchronous processing models (such as Spring WebMVC). For pure asynchronous reactive architectures (Reactive) that pursue extreme throughput, we chose to prioritize ecosystem compatibility (such as seamless integration with Druid/HikariCP), and made compromises on the I/O model.
Best Practice Summary:
After extensive adaptation practices, I found that the best path to realize "One API" is to rely on standard DSLs or Shell Commands provided by database vendors.
- If the database itself provides a stable text protocol (such as SQL, MongoDB Shell Command, Elasticsearch DSL), then building adapters based on these standard protocols to interface with underlying APIs is the most robust and compatible way.
- For databases without DSL, just imitate its API calling method and provide a Shell Command. This point can learn from MongoDB's idea.
VIII. dbVisitor Practical Demonstration
To let everyone feel the charm of "One API" more intuitively, taking the most common CRUD operations as an example, showing how dbVisitor maintains a unified coding experience across different data sources.
1. Unified CRUD Experience
Regardless of whether the underlying is MySQL, MongoDB, or Elasticsearch, developers can use completely consistent APIs for data operations.
// Initialization (Only need to change Connection creation method)
// Connection conn = DriverManager.getConnection("jdbc:mysql://...");
// Connection conn = DriverManager.getConnection("jdbc:dbvisitor:mongo://...");
Connection conn = DriverManager.getConnection("jdbc:dbvisitor:elastic://...");
LambdaTemplate template = new LambdaTemplate(conn);
// 1. Insert Data (Insert)
UserInfo user = new UserInfo();
user.setId("1001");
user.setName("dbVisitor");
template.insert(UserInfo.class)
.applyEntity(user)
.executeSumResult();
// 2. Query Data (Select)
// Auto Adapt: MySQL WHERE / Mongo Filter / ES BoolQuery
List<UserInfo> list = template.query(UserInfo.class)
.eq(UserInfo::getName, "dbVisitor")
.list();
// 3. Update Data (Update)
template.update(UserInfo.class)
.eq(UserInfo::getId, "1001")
.updateTo(UserInfo::getName, "Updated Name")
.doUpdate();
// 4. Delete Data (Delete)
template.delete(UserInfo.class)
.eq(UserInfo::getId, "1001")
.doDelete();
2. Underlying API Reachable (Escape Hatch)
When the unified API cannot meet special needs (such as Redis specific atomic operations, or ES special aggregations), dbVisitor allows "penetrating" to the underlying driver through the unwrap mechanism and directly using the native SDK.
// Scenario A: Redis Native Call (Penetrate to Jedis)
if (conn.isWrapperFor(Jedis.class)) {
Jedis jedis = conn.unwrap(Jedis.class);
jedis.set("native_key", "value");
// Use all Jedis native capabilities...
}
// Scenario B: Elasticsearch Native Call (Penetrate to RestClient)
if (conn.isWrapperFor(RestClient.class)) {
RestClient client = conn.unwrap(RestClient.class);
// Construct native Request...
Request request = new Request("GET", "/user_index/_search");
request.setJsonEntity("{\"query\":{\"match_all\":{}}}");
client.performRequest(request);
}
IX. dbVisitor Ecosystem Status
Currently, dbVisitor has achieved unified access support for multiple types of data sources and is step by step fulfilling the promise of the new generation data access library:
- Relational Databases:
- Supports mainstream relational databases such as MySQL, PostgreSQL, Oracle, SQLServer, H2, SQLite, etc.
- NoSQL Support:
- Elasticsearch: Supports complex index queries and aggregations.
- MongoDB: Supports document CRUD and complex filtering.
- Redis: Abstracts Redis into data tables for operation.
In dbVisitor's world, developers no longer need to refactor the entire data access layer code to introduce a new middleware. One API, Access Any DataBase, this is not just a slogan.
If you are looking for a solution that can unify the management of relational and non-relational data access, why not try dbVisitor and experience the development efficiency revolution brought by the new generation data access library.